Apache Kafka - Fetch Request & Replication Protocol

The previous post explained how a Produce Request is written to the leader node. In this post, I’d like to explore how followers in Kafka replicate data from the leader node, and how the leader node tracks the replication status of each follower.
Replication Protocol
In the previous post, we mentioned that when acks = -1, the leader must wait until at least min.insync.replicas followers have replicated the batch before sending the write result back to the producer. But have you ever wondered: is Kafka using a Push Model, where the leader actively sends requests to followers, or a Pull Model, where followers request data from the leader?
The answer is Pull Model, and here’s why:
In a Push Model, the leader would have to track the state of every follower. How would it know when to start a task and from which offset to send data to a follower? It would also need to handle replication errors — for example, if a follower stops responding, should the Leader halt replication, or keep retrying and wasting resources? All of this would add significant complexity to the Leader’s implementation.
In a Pull Model, followers fetch data from the leader using fetch requests. Kafka has optimized the fetch request path with zero-copy, allowing data to be written directly from disk to the NIC buffer without passing through user-space memory. This makes the Pull Model more memory-efficient.
Kafka’s initial choice of the Pull Model also influenced the later implementation of KRaft, which likewise uses the Pull Model. If you’ve read about the Raft consensus algorithm, you’ve probably noticed that it typically uses a Push Model, where the leader sends heartbeat requests to prevent followers from triggering elections. However, the KRaft algorithm chose to stick with the Pull Model and reuse the same RPC mechanism used for normal log replication — namely, the fetch request — to avoid maintaining two different replication methods.
If you noticed in the previous discussion that produce request listeners only support brokers, you may also have observed that fetch requests support both brokers and controllers. This is because KRaft Followers also fetch logs via fetch requests.
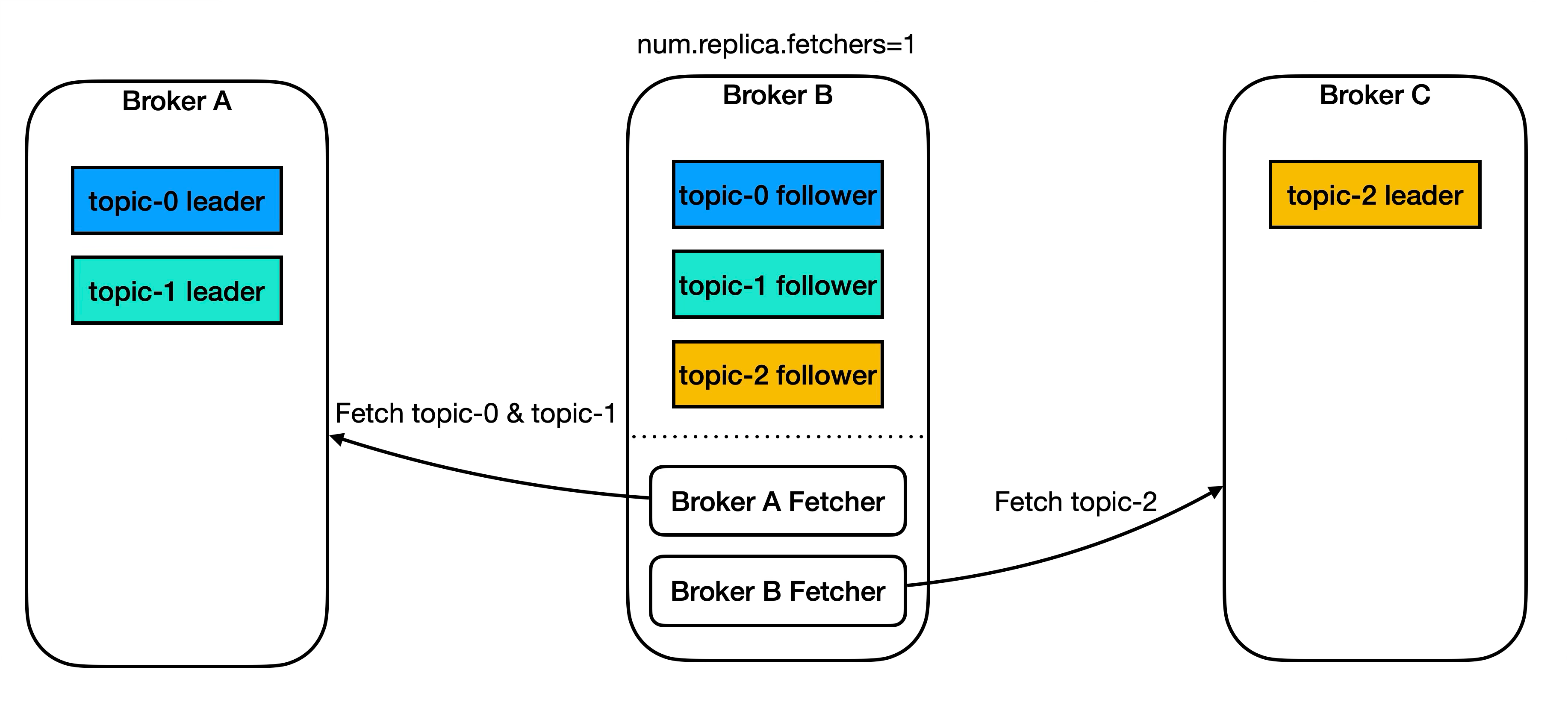
Since Kafka relies on followers actively pulling data from the leader, how do followers internally manage these replication tasks? Inside each follower, Kafka starts num.replica.fetchers threads per broker (with a default of 1). For example, if Broker A hosts two partition leaders and Broker B holds replicas of both partitions, then by default Broker B launches just one thread to issue fetch requests for both partitions.
It’s worth noting that before Kafka 4.2.0, there was no check to ensure num.replica.fetchers ≤ 0 was invalid. If you accidentally misconfigured this parameter, the system wouldn’t raise any warnings. Fortunately, this has been fixed in KAFKA-19645.
Fetch Request
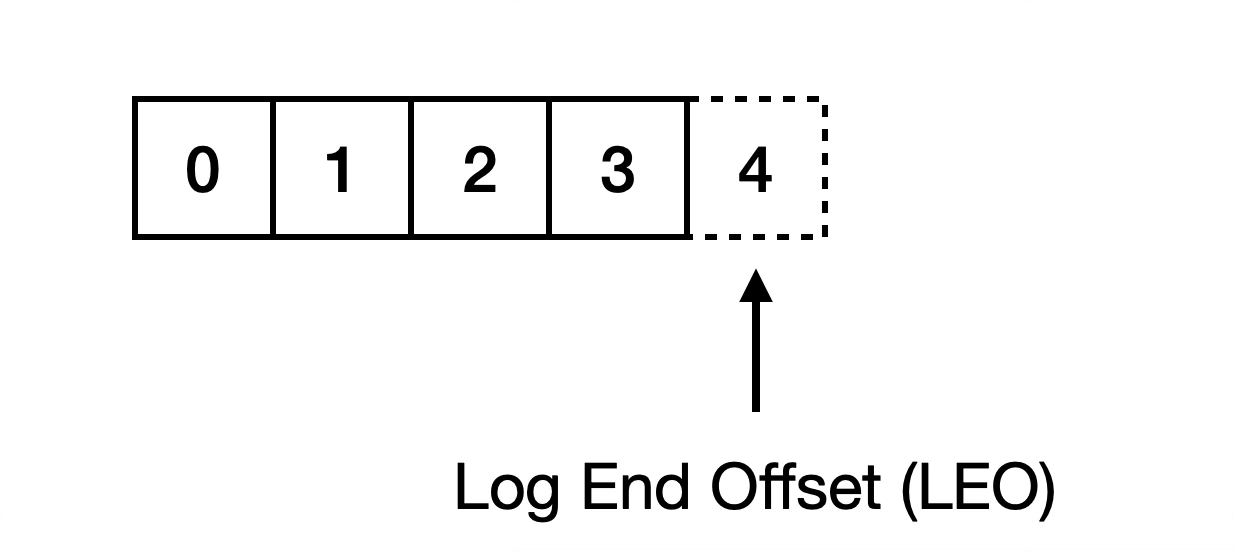
Replication is actually divided into two parts. The first part is truncate. A follower retrieves the partition leader epoch of its current last log entry and uses an OffsetForLeaderEpochRequest to query the Log End Offset (LEO) corresponding to that epoch. LEO represents the offset immediately after the last record with data. The follower uses this LEO to check for data conflicts and deletes any conflicting records if necessary.
This process will be explained in detail in the next article about how Kafka handles conflicting data. However, there's an improvement worth mentioning in advance: starting from Kafka 2.7, FetchRequest can also detect diverging epochs (KIP-595), meaning FetchRequest itself can perform truncation. In Kafka 4.0, only KRaft is supported, so the minimum supported version is 3.3. In theory, OffsetForLeaderEpochRequest is no longer needed, but if you look at the Kafka 4.0 codebase, you’ll still see this RPC because the related code hasn’t been removed yet. If you’re interested, keep an eye on KAFKA-18477.
Once there’s no conflicting data, the Follower begins synchronizing data using a fetch request. Similar to the produce request mentioned earlier, when examining a new RPC, it’s best to first look at its fields. The fetch request protocol is defined in FetchRequest.json.
Like produce requests, a single fetch request can include multiple topic partitions. Each partition in the request has a FetchOffset, which indicates the starting point from which the follower wants to replicate data. In fact, FetchOffset essentially represents the follower’s LEO. When the Leader receives this request, it returns the corresponding records. For example, if the FetchOffset is 101, the leader will send records 101–113. Once the follower writes these records successfully, its next fetch request will carry a FetchOffset of 114.
Earlier, we talked about the drawbacks of the Push Model. So what’s the downside of the Pull Model? The main issue is that a follower can’t be sure whether the leader has new data, so it must repeatedly send fetch requests to check, increasing network overhead.
To mitigate this, when the leader receives a fetch request but has no new data yet, it holds the request open for a short period (configured by replica.fetch.wait.max.ms, default 500 ms). If no new records arrive within this time window, only then does the leader return an empty fetch response. It’s important to note that this wait time is specified by the follower in the fetch request itself, so the parameter must be configured on the follower’s machine.
High Watermark
After a follower finishes replicating data, how does the Leader keep track of the replication progress of each partition?
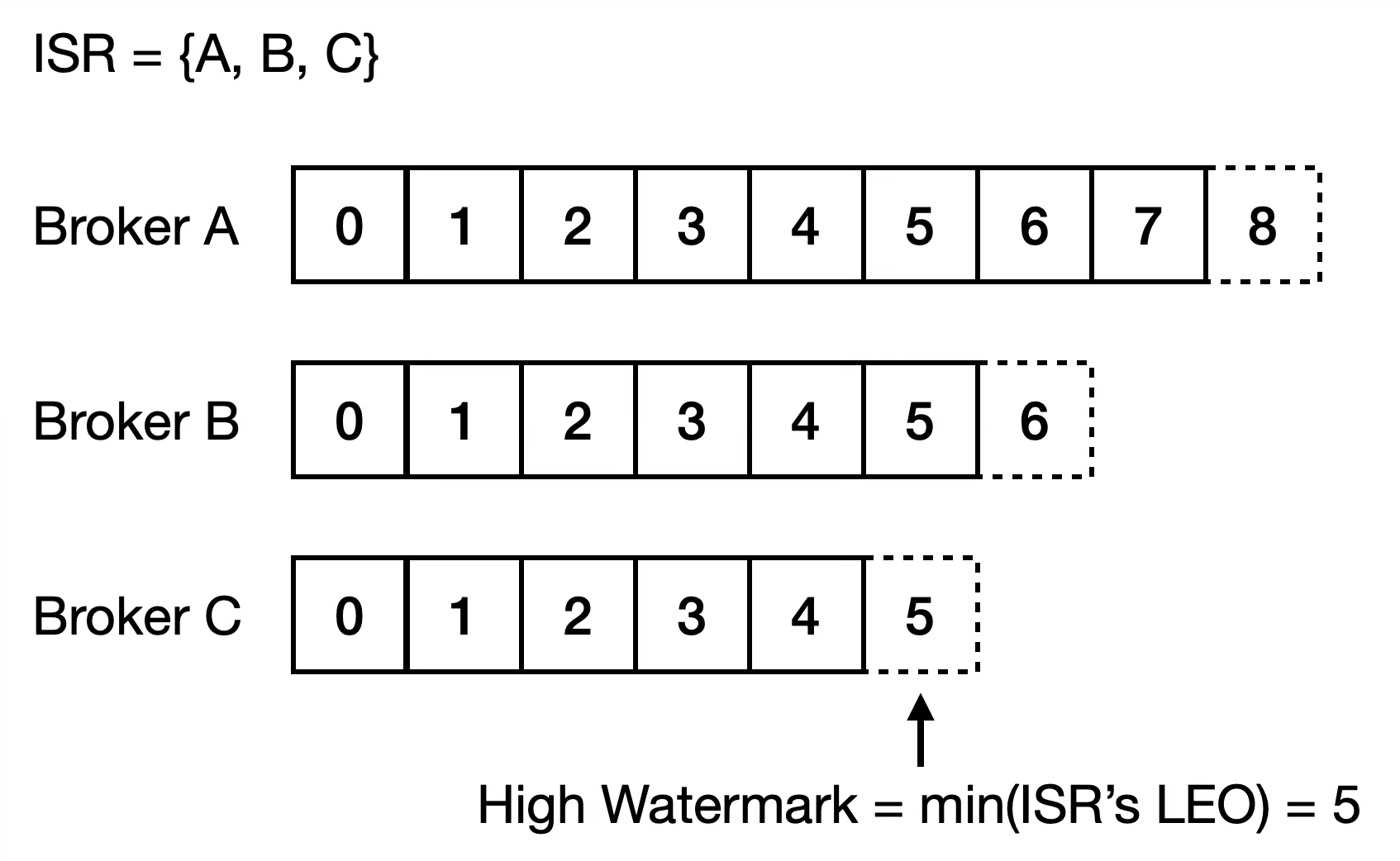
Kafka uses a concept called the High Watermark (HW). The HW represents the LEO of the slowest Follower within the In-Sync Replica (ISR) set. (We’ll introduce ISR in the next section; for now, just focus on what HW means.)
For example, suppose:
Leader’s LEO = 8
Follower A’s LEO = 6
Follower B’s LEO = 5
In this case, the High Watermark is 5.
How does the leader know the current LEO of a follower? The answer lies in the Fetch Request’s FetchOffset. When the leader receives a fetch request, it maintains a ReplicaState for each follower. Inside this state, there’s a field called logEndOffsetMetadata, which represents the follower’s LEO — effectively the same as the FetchOffset. The update path for this value is implemented in Replica#updateFetchStateOrThrow, and afterward, the leader updates the high watermark through Partition#maybeIncrementLeaderHW.
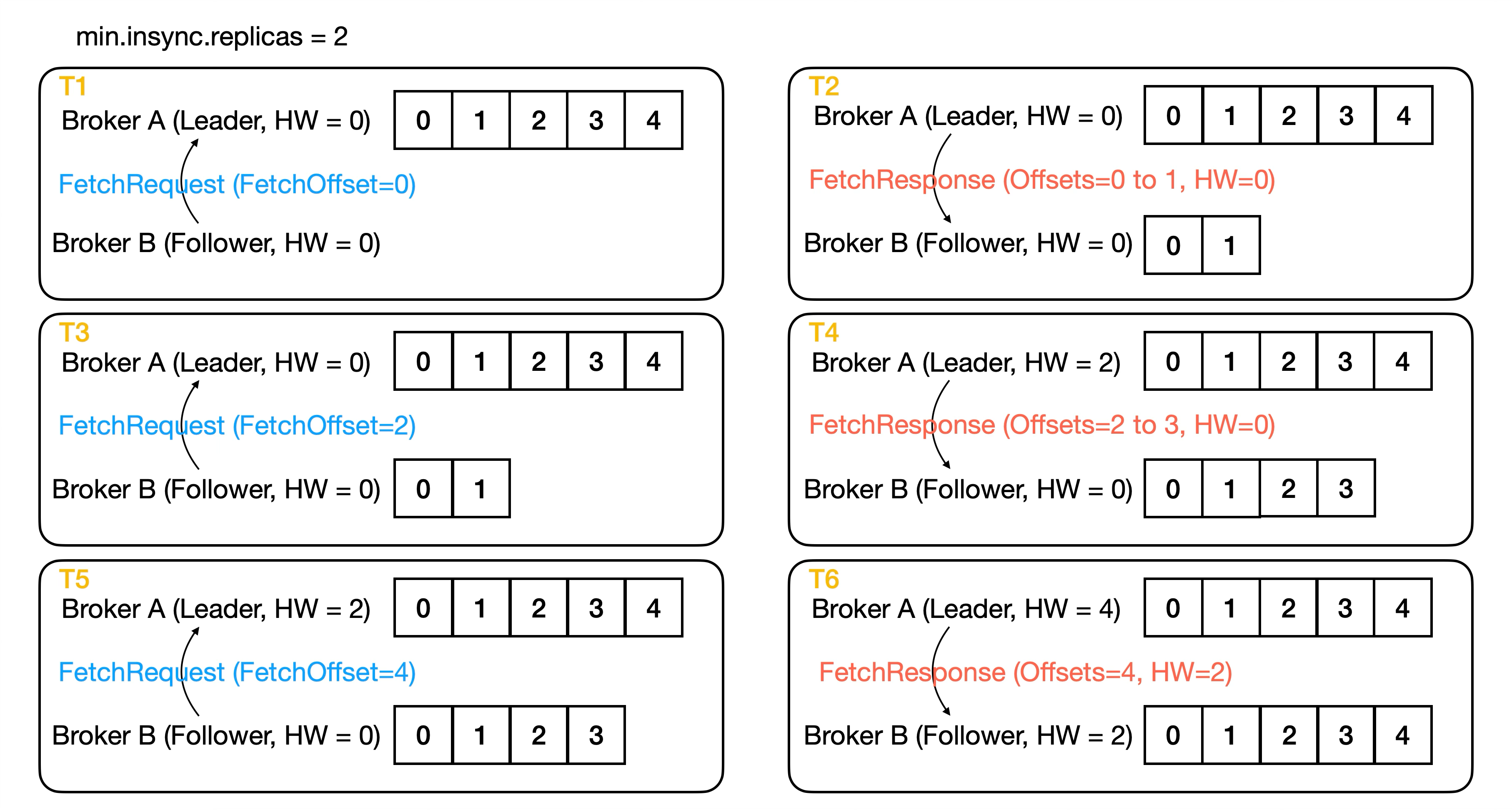
It’s important to note that the leader updates HW based on the FetchOffset, not just because it has sent data back in a Fetch Response. Returning data doesn’t guarantee that the follower has successfully written it to disk. The leader can only be certain of the follower’s replication progress when it sees the next fetch request carrying an updated FetchOffset.
For example, in the diagram you mentioned:
At T2, the leader replies with a fetch response containing records up to offset 1. The leader cannot yet update the HW at this point.
At T3, when it receives the next fetch request, and after processing it at T4, can the leader confirm the follower’s LEO and safely update the high watermark.
After explaining how the leader updates its high watermark, how does a follower update its own high watermark? And why does a follower need to maintain a high watermark at all?
In Kafka, consumers can also fetch data from followers. However, if a piece of data is exposed before being replicated to multiple followers, a consumer might read data that could later disappear. For example, suppose a record exists only on leader A and follower B. If both nodes fail and cannot recover, follower C may be elected as the new leader. Since leader C does not have that record, the consumer’s logic could be broken. This is why followers must also track high watermark information.
The way a follower updates its high watermark is actually straightforward. In FetchResponse.json, there is a HighWatermark field. This means that when the leader returns a fetch response, it includes its own high watermark. When a follower receives this response, as long as the leader’s high watermark ≤ the follower’s own LEO, the follower can directly update its high watermark to the value provided by the leader.
As shown in the figure, at time T4, the follower receives a fetch response and writes offsets 3 and 4, but its high watermark remains at 0. This is because it must wait for the leader to update its high watermark first. Then, in the next fetch response (T6), once it receives the leader’s updated high watermark, the follower updates its own high watermark accordingly.
In-Sync Replica (ISR)
ISR represents the set of followers that are currently in sync. Kafka defines “in sync” as follows: once a follower is already part of the ISR, it remains in the ISR as long as it does not fall behind for longer than replica.lag.time.max.ms.
You might wonder: if the leader keeps receiving a heavy stream of writes, and a follower is always just one record behind the leader’s latest data, will that follower be kicked out of the ISR? Kafka has an elegant solution for this.
As mentioned earlier, when the leader receives a fetch request, it records the follower’s ReplicaState. This state contains two important fields:
lastFetchTimeMs: the timestamp when the fetch request was received.lastFetchLeaderLogEndOffset: the leader’s LEO at that timestamp.
As long as the follower eventually catches up to that LEO, the leader calculates the current time minus the lastFetchTimeMs associated with that LEO. If this result is less than replica.lag.time.max.ms, the follower will not be removed from the ISR. For more details, see the logic in Partition#getOutOfSyncReplicas.
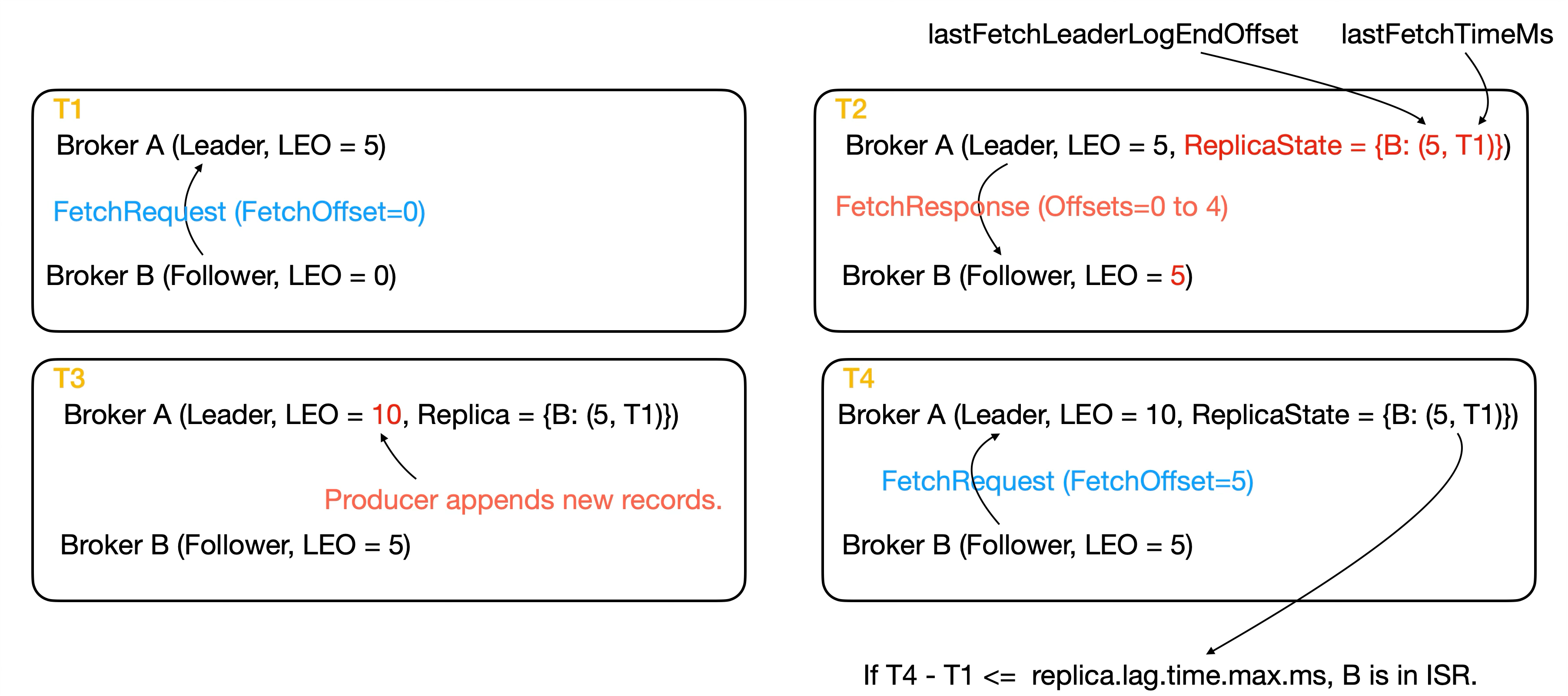
If a follower is not part of the ISR, to which log offset must it catch up in order to rejoin? As long as the follower replicates up to the leader’s high watermark, and that high watermark belongs to the current leader epoch, the Follower can rejoin the ISR. In earlier Kafka versions, a follower only needed to catch up to the leader’s high watermark to rejoin the ISR. However, KAFKA-7128 documents an edge case where this condition alone could cause the high watermark to continuously move backward. If you’re interested, you can check the linked example for details.
What happens if the number of replicas in the ISR for a topic partition falls below min.insync.replicas? This means the high watermark can no longer advance. If a producer continues to write with acks = -1, will data start to pile up? The answer is no. When the ISR size drops below min.insync.replicas, Kafka disallows writes from producers and returns a NotEnoughReplicasException.
Takeway
Kafka’s replication protocol uses a Pull Model.
Each broker can create up to
num.replica.fetchersfetcher threads for every remote broker.The data below the High Watermark represents what is readable by the consumer and can be accessed using read_uncommitted. If transactions are used, there is another concept called the Last Stable Offset (LSO), which indicates the position readable with read_committed. This will be introduced in a later article.
The leader updates its High Watermark using the
FetchOffsetprovided in followers’ fetch requests.Followers update their own high watermark using the value included in the leader’s fetch response.
The leader records its LEO and timestamp for every fetch request. Once a follower catches up to that LEO, the leader uses that timestamp to determine whether the follower can remain in the ISR.
When acks=-1, if ISR < min.insync.replicas, Kafka will return a
NotEnoughReplicasException, indicating that data cannot be written.
上一篇分享了 Produce Request 寫入 Leader 節點的過程,這一篇主要想探討,在 Kafka 裡面的 Follower 是如何從 Leader 節點複製資料的,以及 Leader 節點如何知道每個 Follower 複製的狀態。
Replication Protocol
上一篇有提到當 Acks = -1 時,Leader 要等到有至少 min.insync.replicas 個 Follower 複製到這個 Batch,才能將寫入結果回傳給 Producer,那你有思考過,究竟是 Push Model:Leader 主動發 Request 給 Follower,還是 Pull Model:Follower 發 Request 給 Leader 請求資料呢?
答案是 Pull Model,原因如下:
Push Model 情況下,Leader 要追蹤 Follower 狀態,像是 Leader 該如何知道何時要啟動一個 Task 並從哪裡開始複製資料給 Follower 呢?還要處理複製錯誤的部分,像是 Follower 一直沒回應,Leader 該停止,還是繼續耗費資源進行重試呢?這些都會提高實作 Leader 的複雜度。
Pull Model 情況下,Follower 會透過 Fetch Request 去跟 Leader 拿資料,Kafka 針對 Fetch Request 的路徑有做 Zero-Copy 優化,資料可以直接從 Disk 寫到 NIC buffer,所以 Pull Model 會更節省記憶體。
Kafka 一開始選擇 Pull Model,也間接影響到後來實作 KRaft 時,也使用 Pull Model,如果有讀過 Raft 算法,大部分情況下看到的應該都是 Push Model,Leader 會發送 Heartbeat Request 避免 Follower 發起選舉,但 KRaft 算法選擇維持 Pull Model,並且使用一般 Log 複製時使用的 RPC,也就是 Fetch Request,藉此避免維護兩種不同的複製方法。如果你有注意到上一篇 Produce Request 的 listeners 只支援 broker 的話,那你一定也注意到了 Fetch Request 支援 broker 跟 controller,原因就是 KRaft 的 Follower 也是透過 Fetch Request 去拿 Log。
既然 Kafka 裡面是讓 Follower 主動去跟 Leader 拿資料,那 Follower 裡面又是如何管理這些複製的工作的呢?在 Follower 裡面,會對每個 Broker 啟動 num.replica.fetchers 個 Thread,預設值是 1,假設 Broker A 有兩個 Partition Leader,Broker B 也維護這兩個 Partition 的副本,那在預設情況下,Broker B 也只會啟動一個 Thread 來發起這兩個 Partition 的 Fetch Request。要注意在 Kafka 4.2.0 以前,並沒有檢查 num.replica.fetchers 是不是 ≤ 0,如果不小心設置錯的話,不會有系統警告,幸好在 KAFKA-19645 已經修正了。
Fetch Request
Replication 其實分兩部分,第一部分是 Truncate,Follower 會抓目前最後一條 Log 的 Partition Leader Epoch,並使用 OffsetForLeaderEpochRequest 詢問這個 Epoch 對應的 Log End Offset (LEO),LEO 代表最後一個有資料的 Offset+1,Follower 會用 LEO 去判斷資料是否有衝突,有的話先將衝突的資料刪掉,這部分會放到下一篇專門講 Kafka 如何處理衝突資料,不過有個正在改進的東西可以先提一下,在Kafka 2.7 之後,FetchRequest 也可以偵測 Diverging Epoch (KIP-595),所以 FetchRequest 本身就能做到 Truncate 了,而在 4.0 之後只支援 KRaft,所以最低支援的 Kafka 版本是 3.3,理論上 OffsetForLeaderEpochRequest 已經不需要了,但如果看 4.0 的 code 還是這個 RPC,因為這部分的 code 暫時還沒刪除,如果有興趣,可以關注 KAFKA-18477。
沒有衝突資料後,Follower 就會用 Fetch Request 開始同步資料,跟上一篇提到的 Produce Request 一樣,看一個新的 RPC 時,建議先從 Request 有哪些欄位開始看,Fetch Request Protocol 記錄在 FetchRequest.json。Fetch Request 跟 Produce Request 一樣,一個 Request 就可以包含多個 Topic Partition 的資料,每個 Topic Partition 都有一個 FetchOffset,Follower 會用這個值來代表接下來要複製的起始位置,FetchOffset 其實就代表 Follower 的 LEO,Leader 收到後就會回傳相對應的資料,假設 FetchOffset 是 101,Leader 回傳 101–113 的資料並且 Follower 成功寫入後,下一次 Follower 就會發送 FetchOffset 114。
前面有提到 Push Model 的缺點,那 Pull Model 有什麼缺點嗎?Pull Model 的缺點就是 Follower 不確定 Leader 是否有新資料,所以只能不斷地發送 Fetch Request 詢問,造成更多網路開銷,為了避免 Follower 一直收到空的回傳,Leader 在收到 Fetch Request 時,如果暫時沒有新的資料,會將這個 Request 暫時擱置 replica.fetch.wait.max.ms,預設是 500ms,如果時間到還是沒資料,才回傳 Fetch Response,不過要注意這個等待時間是由 Follower 夾帶在 Fetch Request 的,所以如果要設定這個參數應該在 Follower 機器上設定。
High Watermark
Follower 複製好資料後,Leader 如何維護目前 Partition 複製的進度呢?在這裡 Kafka 定義了一個概念叫做 High Watermark,代表 In-Sync Replica (ISR) 裡面,複製進度最慢的 Follower 的 LEO,ISR 是個新的概念,下一段在介紹,這邊只要先知道 High Watermark 的意思即可,假設 Leader 的 LEO 是 8,Follower A 是 6,Follower B 是 5,那 High Watermark 就是 5。
那 Leader 是怎麼知道 Follower 目前的 LEO 的?答案是透過 Fetch Request 的 FetchOffset,當 Leader 收到 Fetch Request 後,會幫每個 Follower 維護一份 ReplicaState,裡面有一個欄位是 logEndOffsetMetadata,就代表 Follower 的 LEO,也代表 FetchOffset,具體更新路徑在 Replica#updateFetchStateOrThrow,隨後 Leader 會透過 Partition#maybeIncrementLeaderHW 來更新 High Watermark。
這邊要注意 Leader 是拿 FetchOffset 來更新 High Watermark,Leader 不能因為 Fetch Response 要回傳更新的資料,就當作 Follower 一定要寫入成功,所以 Leader 要等到 Follower 的下一個 Fetch Request 裡面的 FetchOffset,才能知道 Follower 目前複製的狀況,進而更新 High Watermark。以下圖為例,Leader 在 T2 回覆 Fetch Response 時,已經夾帶 offset 1 以前的資料,但此時還不能更新 High Watermark,要等到 T3 收到下一個 Fetch Request,然後 T4 處理過後才更新 High Watermark。
說明完 Leader 如何更新 High Watermark 後,那 Follower 又是如何更新 High Watermark 的呢?以及為什麼 Follower 也要維護 High Watermark 呢?在 Kafka 裡面,Consumer 也可以透過 Follower 獲取資料,但如果一筆資料還沒被複製到多個 Follower 就對外提供這筆資料的話,Consumer 可能會拿到之後可能不存在的資料,像是某筆資料只有 Leader A 跟 Follower B 有,但因為系統損壞,這兩個節點都無法恢復,改由 Follower C 來擔任新的 Leader,而 Leader C 並沒有這筆資料,這樣可能導致 Consumer 邏輯出錯,所以 Follower 也必須維護 High Watermark 訊息。
Follower 更新 High Watermark 的方式其實很簡單,在 FetchResponse.json 裡面有 HighWatermark 欄位,代表 Leader 在回傳 Fetch Response 時會夾帶 Leader 的 High Watermark,Follower 收到後只要確定 Leader 的 High Watermark ≤ Follower 自己的 LEO,就可以直接 High Watermark 更新成 Leader 給的值。以上圖為例,Follower 在 T4 時間點收到 Fetch Response 並且寫入 Offset 3 跟 4,但 High Watermark 還是 0,原因是要等到 Leader 先更新 High Watermark,然後下一個 Fetch Response (T6) 收到 Leader 的 High Watermark,Follower 才更新 High Watermark。
In-Sync Replica (ISR)
ISR 代表目前有跟上同步的 Follower,Kafka 對有跟上的定義是,如果一個 Follower 已經是 ISR,那只要不要掉隊超過 replica.lag.time.max.ms,就算是 ISR。
你可能會好奇,假設 Leader 一直持續有大量的資料寫入,而 Follower 每次就是複製不到 Leader 的最後一筆資料時,那 Follower 是不是會被踢出 ISR?Kafka 在這邊做了一個巧妙的設計,前面有提到 Leader 收到 Fetch Request 時,會幫 Follower 紀錄 ReplicaState,裡面有個欄位是 Fetch Request 的時間點 lastFetchTimeMs,另外有個欄位是 lastFetchLeaderLogEndOffset,代表每次 Fetch Request,Leader 都會記錄這個時間點 Leader 的 LEO,只要 Follower 之後同步到這個 LEO,Leader 就會用現在的時間點,減去這個 LEO 對應的 lastFetchTimeMs,只要這個結果小於 replica.lag.time.max.ms,那 Follower 就不會被踢出 ISR,具體路徑可以參考 Partition#getOutOfSyncReplicas。
如果一個 Follower 不是 ISR,那要複製到哪個 Log 才能被加入 ISR?只要 Follower 複製到 Leader 的 High Watermark,並且這個 High Watermark 也在目前的 Leader Epoch 內,Follower 就能被加入 ISR。在早期的版本,只要 Follower 複製到 Leader 的 High Watermark 就能被加入 ISR,但在 KAFKA-7128 有記錄一個 edge case,如果只有這個條件,可能會導致 High Watermark 不斷的往後退,有興趣的可以點進連結看範例。
如果 Topic Partition 的 ISR 數量已經小於 min.insync.replicas,代表 High Watermark 沒辦法再往前推進,如果這時 Producer 還持續用 Acks = -1 寫入,會不會積累大量的資料呢?答案是不會,因為當 ISR 小於 min.insync.replicas,Kafka 就會禁止 Producer 寫入,並回傳 NotEnoughReplicasException。
Takeway
Kafka 的 Replication Protocol 使用的是 Pull Model。
每個 Broker 針對每個外部 Broker,可以建立最多 num.replica.fetchers 個 Fetcher Thread。
High Watermark 以下代表 Consumer 可讀的資料,可以用 read_uncommitted 讀到。如果使用 Transaction 的話,有另一個概念是 Last Stable Offset (LSO),代表 read_committed 可以讀到的位置,會在之後的文章在介紹。
Leader 透過 Follower Fetch Request 夾帶的
FetchOffset來更新 High Watermark。Follower 透過 Fetch Response 夾帶的 High Watermark 更新自己的 High Watermark。
Leader 會記錄每個 Fetch Request 當下 Leader 的 LEO 以及 Timestamp,只要 Follower 之後跟上這個 LEO,就能用這個 Timestamp 去計算還能不能在 ISR 內。
acks=-1 時,如果 ISR < min.insync.replicas,Kafka 會回傳
NotEnoughReplicasException,代表無法寫入資料。